Basics:
Multi-Armed Bandit Problem:
In probability theory, the Multi-Armed Bandit Problem (sometimes called the K-[1] or N-armed bandit problem is a problem in which a gambler at a row of slot machines (sometimes known as "one-armed bandits") has to decide which machines to play, how many times to play each machine and in which order to play them. When played, each machine provides a random reward from a probability distribution specific to that machine. The objective of the gambler is to maximize the sum of rewards earned through a sequence of lever pulls.
In practice, multi-armed bandits have been used to model the problem of managing research projects in a large organization. Given a fixed budget, the problem is to allocate resources among the competing projects, whose properties are only partially known at the time of allocation, but which may become better understood as time passes.

In early stages of this problem, the gambler has no initial knowledge about the machines. The crucial tradeoff the gambler faces at each trial is between
- "exploitation" of the machine that has the highest expected payoff and
- "exploration" to get more information about the expected payoffs of the other machines.
The trade-off between exploration and exploitation is also faced in reinforcement learning.

Upper Confidence Bound Algorithm:

Code:Upper Confidence Bound
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Ads_CTR_Optimisation.csv')
# Implementing UCB
import math
N = 5
d = 10
ads_selected = []
numbers_of_selections = [0] * d #Vector of size d
sums_of_rewards = [0] * d
total_reward = 0
for n in range(0, N):
ad = 0
max_upper_bound = 0
for i in range(0, d):
if (numbers_of_selections[i] > 0):
average_reward = sums_of_rewards[i] / numbers_of_selections[i]
delta_i = math.sqrt(3/2 * math.log(n + 1) / numbers_of_selections[i])
upper_bound = average_reward + delta_i
else:
upper_bound = 1e400
if upper_bound > max_upper_bound:
max_upper_bound = upper_bound
ad = i
ads_selected.append(ad)
numbers_of_selections[ad] = numbers_of_selections[ad] + 1
reward = dataset.values[n, ad]
sums_of_rewards[ad] = sums_of_rewards[ad] + reward
total_reward = total_reward + reward
# Visualising the results
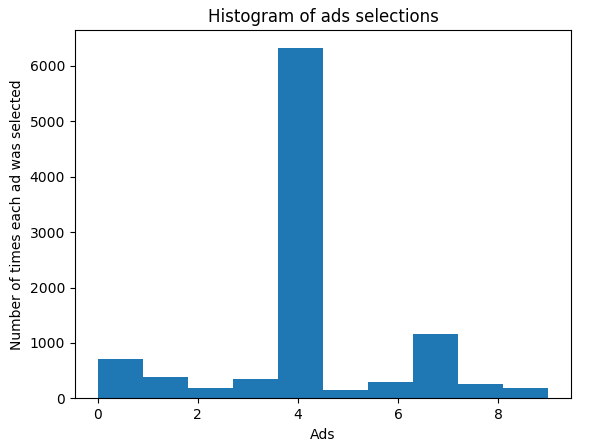
plt.hist(ads_selected)
plt.title('Histogram of ads selections')
plt.xlabel('Ads')
plt.ylabel('Number of times each ad was selected')
plt.show()

Hope this helps!!
Arun Manglick
Multi-Armed Bandit Problem:
In probability theory, the Multi-Armed Bandit Problem (sometimes called the K-[1] or N-armed bandit problem is a problem in which a gambler at a row of slot machines (sometimes known as "one-armed bandits") has to decide which machines to play, how many times to play each machine and in which order to play them. When played, each machine provides a random reward from a probability distribution specific to that machine. The objective of the gambler is to maximize the sum of rewards earned through a sequence of lever pulls.
In practice, multi-armed bandits have been used to model the problem of managing research projects in a large organization. Given a fixed budget, the problem is to allocate resources among the competing projects, whose properties are only partially known at the time of allocation, but which may become better understood as time passes.

In early stages of this problem, the gambler has no initial knowledge about the machines. The crucial tradeoff the gambler faces at each trial is between
- "exploitation" of the machine that has the highest expected payoff and
- "exploration" to get more information about the expected payoffs of the other machines.
The trade-off between exploration and exploitation is also faced in reinforcement learning.


Code:Upper Confidence Bound
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Ads_CTR_Optimisation.csv')
# Implementing UCB
import math
N = 5
d = 10
ads_selected = []
numbers_of_selections = [0] * d #Vector of size d
sums_of_rewards = [0] * d
total_reward = 0
for n in range(0, N):
ad = 0
max_upper_bound = 0
for i in range(0, d):
if (numbers_of_selections[i] > 0):
average_reward = sums_of_rewards[i] / numbers_of_selections[i]
delta_i = math.sqrt(3/2 * math.log(n + 1) / numbers_of_selections[i])
upper_bound = average_reward + delta_i
else:
upper_bound = 1e400
if upper_bound > max_upper_bound:
max_upper_bound = upper_bound
ad = i
ads_selected.append(ad)
numbers_of_selections[ad] = numbers_of_selections[ad] + 1
reward = dataset.values[n, ad]
sums_of_rewards[ad] = sums_of_rewards[ad] + reward
total_reward = total_reward + reward
# Visualising the results
plt.hist(ads_selected)
plt.title('Histogram of ads selections')
plt.xlabel('Ads')
plt.ylabel('Number of times each ad was selected')
plt.show()
Hope this helps!!
Arun Manglick
No comments:
Post a Comment